
介绍
这篇文章将介绍许多在游戏中使用的人工智能概念,您将了解有哪些工具可用于解决AI问题,它们如何协同工作,以及您将如何在您选择的语言或引擎中实现这些工具。
这篇论文要求你对游戏有基本的了解,掌握一些数学概念,比如几何,三角函数等等。引用的代码例子都是虚拟代码,不需要有专门的编程语言水平。
什么是游戏AI?
游戏AI主要解决游戏角色根据当前条件应该做出什么动作。传统AI环境中所指的智能体通常是游戏中的人,现在也可以指汽车、机器人或者更抽象的,比如一群目标对象、一个国家或者一个人口。他们都需要观察周围的环境,并根据环境做出决策和执行行动。通常这个过程是一个感知/思考/行动的循环。
感觉:一个智能体检测到或被告知环境中可能影响其行动的物体(附近有危险,要捡的物体,要检查的地方)。
思考:代理人要想出应对的办法(比如选择一个安全的时间拿东西,或者决定先攻击还是先躲)。
行动:代理将先前的决定付诸行动(例如,开始向敌人或目标对象移动)。
环境变化,用新数据重复这个循环.
在真正的AI问题中,大部分公司关注的是“感知”环节。例如,自动驾驶汽车必须拍摄前方道路的照片,并与雷达或激光雷达数据进行比较,然后尝试解读看到的内容。这通常是通过机器学习方法来完成的。
游戏就不一样了,因为不需要复杂的系统来提取信息,因为大部分信息都在模拟系统内部。我们不需要运行图片识别算法来找到敌人的位置;游戏知道敌人在哪里,可以直接把信息反馈给决策过程。所以游戏中的“感知”环节比较简单,但是最后两步比较难。
游戏人工智能的发展限制
游戏中的AI通常面临以下限制:
它通常不会像机器学习算法那样被“预先训练”;写一个神经网络去观察成千上万的玩家并学习是不现实的,因为在游戏还没有发布的时候,这种方法是不可能的。
游戏应该是有趣的,有挑战性的,而不是“最好的”。所以,即使智能体的水平可以超越人类,也不会是设计师追求的目标。
特工不能太“机械”,让对手真的认为他的队友是“人”而不是“机器”。AlphaGo虽然强大,但是和它对弈的棋手都觉得它的下棋方法很不一般,感觉像和外星人对弈。所以游戏AI也要调整得更“拟人化”。
要支持实时处理,算法不能为了想出对策而长时间占用GPU。十毫秒太长了。
理想的系统是数据驱动的,而不是硬编码的,这样即使不会编程的人也能做出调整。
有了这些原则,我们就可以开始研究在感知、思考和行动的循环中使用的简单人工智能方法。
基本决策
我们以简单的游戏《乓》为例,保证乒乓球能在球拍上弹起,掉下来就没了。人工智能的任务是决定球拍的方向。
硬编码条件语句
如果我们用AI来控制球拍,那么最直接简单的方法就是尽量把球拍保持在乒乓球下面。球碰到球拍时,球拍的位置是合适的。
由虚拟代码表示:
游戏运行时的每一帧/更新:
如果球在球拍的左边:
向左移动桨
否则,如果球在球拍的右边:
向右移动桨
这个方法太简单了,但是在代码中:
感知部分有两个“如果”语句。游戏知道球和球拍的位置,所以AI问游戏的位置来感知球的方向。
“思考”部分也在两个“如果”语句中。它涉及两个决定,这两个决定将最终决定是否向左、向右移动球拍。
“动作”在代码中表示为向左或向右移动。但在其他场景中,可能包括移动的速度。
我们称这种方法为“反应式”,因为规则很简单。
决策图表
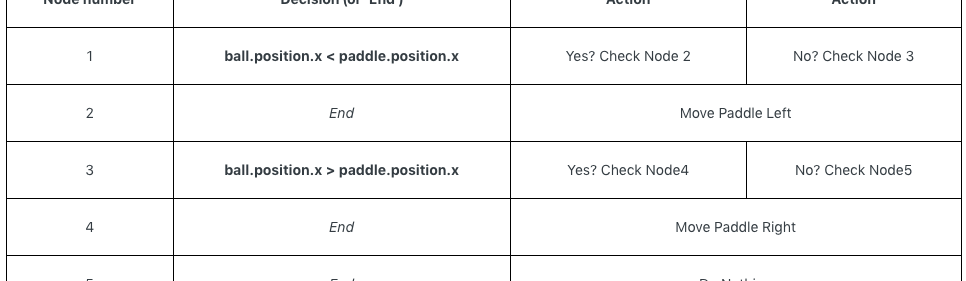
乒乓球比赛也可以通过决策树模型可视化:
乍一看,你可能认为决策树和if语句没有区别。但在这个系统中,每个决策都包括一个确切的条件和两个可能的输出,这使得开发人员可以从表示决策树的数据中构建AI,而无需硬编码。用一个简单的表格来描述决策树是这样的:
如果样本很多,决策树真的很厉害,能高效区分情况。
剧本写作
设计AI的人可以按照自己的想法排列决策树,但必须依赖程序员提供的所需条件和动作。如果我们给设计师更好的工具来创造他们自己的条件呢?
程序员可以把条件(球在球拍的左边还是右边)改成某个值,决策树的数据可能是这样的:
与上表相同,但决策有自己的代码。此外,将这样的表达式(用脚本语言而不是数据)带入逻辑结论是可能的,也是常见的。
响应事件
上面的乒乓球比赛,核心思想是保持三步循环跑,根据上一步的环境状态采取行动。但在更复杂的游戏中,更多的是对情境的反应,而不是对各种条件的评估,这在游戏场景的转换中非常常见。
比如射击游戏,敌人一开始是静止的。一旦他们找到了玩家,不同角色的敌人就会采取不同的行动。冲锋队可能会攻击玩家,狙击手会在后方准备射击。这也是一个基本的应对系统,但需要更高级的决策过程。
高级决策
有时,我们希望根据代理的当前状态做出不同的决策。对于决策树或者脚本来说,条件太多是不可能高效运行的。有时候,我们要提前思考,预估环境会如何变化,所以需要更复杂的方法。
有限状态机(有限状态机)
有限状态机(FSM)是指一个对象,例如一个AI代理,它当前处于一种状态,然后将转换到另一种状态。因为状态总数是有限的,所以称为“有限状态机”。现实中的一个例子是交通灯。
在游戏中,让守卫巡逻、攻击或逃跑等动作都可以用简单的if语句来表达。但是如果加上状态,比如流浪、寻找、奔跑求救等动作,if条件句就会变得非常复杂。考虑到所有的状态,我们列出了状态之间需要的转换状态。
用可视化图表表示:
分级状态机(分级状态机)
你可能会注意到,上表中的一些过渡状态是相同的,大部分和patrol中的相同,但是最好区分一下。流浪和巡逻都是非战斗状态的一部分,所以我们可以把它们看作是它的“亚状态”:
主要状态
非战斗状态
形象化
行为树(行为树)
在决策过程中,有一个小问题,过渡原则与当前状态密切相关。在很多游戏中,这种方法不是问题,使用上述的层次状态机也可以减少重复。但有时你想有一个通用规则,而不考虑状态。例如,当一个代理的生命值降低到25%时,你可能想快速逃跑。当设计者将此值减少到10%时,您可以更改所有相关的转换状态。
在这种情况下,理想情况下,需要一个系统来确定哪些状态可以存在于其他状态之外,以便在一个地方进行正确的转换。这是行为树。
部署行为树的方式有很多种,但核心思想是一样的:算法从一个“根节点”开始,树中的每个节点代表一个决策或动作。例如,上面提到的保护分层状态机由行为树表示:
你可能会发现,在这个树中,从巡逻状态到游荡状态没有过多的返回,所以你需要引入无条件的“重复”节点:
动作和导航
我们有乒乓球拍移动,后卫打架的例子,但是怎么才能真正移动一段时间呢?如何设定速度,如何避开障碍物,设计路线等等?我们将详细解释这一部分。
控制
从基础层面可以认为,每个主体都有自己的行动速度和方向,他们会在思考阶段计算速度和方向,在行动阶段执行。如果我们知道代理的目的地,我们可以用等式来表示它:
desired _ travel=destination _ positionagent _ position
但是,在更复杂的环境中,简单的方程处理不了,也许是速度太慢,聪明的人会在途中遇到障碍。所以有时候需要考虑加入其他值,让行走动作更加复杂。
找到(达到目的)的方法
在格子里,要想到达目的地,首先要看你周围可移动的格子。下图是一个简单的搜索操作案例。首先,从起点开始搜索,直到找到目的地,然后规划路线:
不过这种寻找方式似乎太浪费了,花了很长时间才找到最佳路线。以下方法在寻路时一次只选择目标坐标方向上的最佳方块,从而减少了许多候选方块:
学习和适应
虽然我们在文章开头提到机器学习在游戏AI中并不经常使用,但是我们也可以借鉴,在设计游戏或者对抗游戏中可能会有用。例如,在数据和概率方面,我们可以使用朴素贝叶斯分类器来检查大量的输入数据,并尝试对其进行分类,以便代理可以对当前情况做出适当的响应。马尔可夫模型等可以用于预测。
知识表示(知识表示)
我们讨论了各种决策、规划、预测的方法,但是如何才能更有效地掌握整个游戏世界呢?我们应该如何收集和组织所有的信息?如何把数据变成信息或者知识?各种游戏的方法不尽相同,但有几种类似的方法可以使用。
标签
标记用于搜索的碎片信息是最常用的方法。在代码中,标签通常由字符串表示,但是如果您知道所有使用的标签,您可以将字符串转换为唯一的数字,从而节省空间并加快搜索速度。
智能目标
有时候,标签并不足以覆盖所有需要的有用信息,所以另一种存储信息的方式是告诉AI它们的替代品,让它们根据自己的需求进行选择。
频率曲线
响应曲线只是一个图表。输入由X轴表示,虚拟值(如“最近的敌人距离”)和输出由Y轴表示,通常范围为0.0到1.0。该图显示了输入和输出之间的映射关系。
黑板
黑板,顾名思义,记录了游戏中每个参与者的寻路动作或决策,其他人也可以使用其中记录的数据。
图像图表
游戏AI往往需要考虑移动到哪里等问题。这类问题通常可以认为是“地理”问题,需要了解环境的形态和敌人的位置。我们需要一种将地形考虑在内并对环境有大致了解的方法,而图像尝试就是为解决这一问题而做出的数据机构。
标签
本文对游戏中用到的AI进行了概括性的讲解,它们的使用场景非常有用。其中一些技术可能并不常见,但它们具有巨大的潜力。由于本文篇幅所限,我们没有详细介绍所有的方法。有兴趣的同学可以参考原文。








